
Literary students and scholars are, traditionally, concerned with the depth of a text, incorporating close reading techniques as the long-established method of interpretation. In this, our digital age, there has also been an expeditious move to incorporating computational methods to the discipline which promotes the concept of ‘distance reading’ as either a supplementary analysis or, more significantly, as a stand-alone method. While these methods seem to be new and innovative, distance reading is unquestionably consistent with Formalist literary theory of the early-twentieth century in its rejection of a subjective, cultural reading and instead, regards the lexical, grammatical and structural matter as pivotal to understanding what literature can show us outside of a ‘close reading’. Recent digital humanities methodologies are appropriated from other disciplines, such as the sciences, to determine that which a humanistic approach cannot gauge. Distant reading methods then, circumvent the ‘hermeneutics of suspicion’ (Ricoeur, 1970) that pervade traditional literary criticism and pedagogy whilst, importantly, having the potential to gather ‘data’ from thousands of texts in a short period of time. Whilst a prominent and influential voice in the promotion of distant reading as a supplement to other literary analysis, Franco Moretti’s methods continue to be endorsed by many other scholarly digital humanists and I will take influence from some of those working in the field of digital humanities to guide this research paper. Faithful to my previous research on the interwar literature of Elizabeth Bowen, I will use some of the quantitative analysis tools advocated by Moretti and others to mine the data. From this, I will compare a small corpora of Bowen’s fictional texts to look for sufficient similarities or themes which were absent from the close readings that I have done in the past that justifies analysing literature in this way. First, I will examine some of the debates within the digital humanities surrounding computerised readings as it is this faction of the digital humanities that gains most attention and what Matthew Jockers calls “the foundation of digital humanities and its deepest root” (2013, p. 15) – this is also the method I will apply later in my own ‘reading’.
Distant Reading:
The multidisciplinary appeal of distant reading is understandable and might just be most advantageous to literature and cultural critics for whom the concept of a computer doing voluminous ‘readings’ might be the most revolutionary (and controversial) concept within the discipline to date. Franco Moretti, considered the biggest advocate of distant reading techniques, is concerned with the ways in which large volumes of literature can be analysed and contextualised through computerised methods and is less concerned with the extracting meaning from the details. Importantly, Moretti and his team are subverting the long-held assumptions about canonical texts, that those deemed canonical are representative of the entire corpora of a certain period; In his 2000 article, ‘Conjunctures on World Literature’;
“the trouble with close reading (in all of its incarnations, from the new criticism to deconstruction) is that it necessarily depends on an extremely small canon… And if you want to look beyond the canon (and of course, world literature will do so: it would be absurd if it didn’t!) close reading will not do it. It’s not designed to do it, it’s designed to do the opposite. At bottom, it’s a theological exercise—very solemn treatment of very few texts taken very seriously” (p. 151).
Simultaneously, Moretti challenges the idea that literature is not an area that ought to be awarded serious academic attention (or at least financial attention) at a time when the world watches as “universities are beaten into the shapes dictated by business” (Warner, 2015). What, not just Moretti, but a large portion of the digital humanities movement proposes is a modernisation of the existing humanities departments within universities; rather than replacing traditional English programs, educational institutions should work to incorporate aspects of the digital in the humanities. Aside from the issue of funding, there lies another, more inherent problem with this; Literature, even that which is judged canonical, rejects any quantifiable criterion by which we can measure in a scientific way other than general threads of shared publishing place or time. Whilst Moretti and his team at the Stanford Lit Lab have certainly identified some patterns or points of interest, I am yet to be convinced that this method could altogether replace a careful and critical close reading. Rather, Moretti, in the most part, seeks to position literature as an indication-point of history – this is literary history, not literary criticism. Certainly, a distant reading of one or two authors may show some threads of interest to the literary critic but this is not a practice unique to the digital humanist, a literary critic could potentially gauge the same information from a traditional reading - Moretti himself calls for distant reading to span much bigger corpora, otherwise, it is just a close reading with computers. Sharon Marcus and Stephen Best, in their article ‘Surface Reading: An Introduction’ (2009), espouse a vision even more determined than Moretti for distant, or what they call ‘surface reading’ aided by computers; “Where the heroic critic corrects the text, a nonheroic [sic] critic might aim instead to correct for her critical subjectivity, by using machines to bypass it, in the hopes that doing so will produce more accurate knowledge about texts” (2009, p. 17). Whilst the piece is widely distributed as an argument for surface reading methodologies and makes substantial arguments for reading that “what lies in plain sight” because it “often eludes observation—especially by deeply suspicious detectives who look past the surface in order to root out what is underneath it.” (p. 18), the overarching narrative of Marcus and Best’s paper suggests that machine-reading literature can circumvent subjectivity and thus lead to a valid criticism. What is very present in its absence in Best and Marcus’ paper is a proposal of the technologies that afford such an objective reading, and furthermore, from own experience and those which I have read elsewhere, any data that is fed into such a machine for a surface reading must first go through the very humanistic process of selection – what data is to be analysed? The methods by which one selects a corpora are subject to varying degrees of subjective selection whether that is based on time period or any other thread of similarity.
The multidisciplinary appeal of distant reading is understandable and might just be most advantageous to literature and cultural critics for whom the concept of a computer doing voluminous ‘readings’ might be the most revolutionary (and controversial) concept within the discipline to date. Franco Moretti, considered the biggest advocate of distant reading techniques, is concerned with the ways in which large volumes of literature can be analysed and contextualised through computerised methods and is less concerned with the extracting meaning from the details. Importantly, Moretti and his team are subverting the long-held assumptions about canonical texts, that those deemed canonical are representative of the entire corpora of a certain period; In his 2000 article, ‘Conjunctures on World Literature’;
“the trouble with close reading (in all of its incarnations, from the new criticism to deconstruction) is that it necessarily depends on an extremely small canon… And if you want to look beyond the canon (and of course, world literature will do so: it would be absurd if it didn’t!) close reading will not do it. It’s not designed to do it, it’s designed to do the opposite. At bottom, it’s a theological exercise—very solemn treatment of very few texts taken very seriously” (p. 151).
Simultaneously, Moretti challenges the idea that literature is not an area that ought to be awarded serious academic attention (or at least financial attention) at a time when the world watches as “universities are beaten into the shapes dictated by business” (Warner, 2015). What, not just Moretti, but a large portion of the digital humanities movement proposes is a modernisation of the existing humanities departments within universities; rather than replacing traditional English programs, educational institutions should work to incorporate aspects of the digital in the humanities. Aside from the issue of funding, there lies another, more inherent problem with this; Literature, even that which is judged canonical, rejects any quantifiable criterion by which we can measure in a scientific way other than general threads of shared publishing place or time. Whilst Moretti and his team at the Stanford Lit Lab have certainly identified some patterns or points of interest, I am yet to be convinced that this method could altogether replace a careful and critical close reading. Rather, Moretti, in the most part, seeks to position literature as an indication-point of history – this is literary history, not literary criticism. Certainly, a distant reading of one or two authors may show some threads of interest to the literary critic but this is not a practice unique to the digital humanist, a literary critic could potentially gauge the same information from a traditional reading - Moretti himself calls for distant reading to span much bigger corpora, otherwise, it is just a close reading with computers. Sharon Marcus and Stephen Best, in their article ‘Surface Reading: An Introduction’ (2009), espouse a vision even more determined than Moretti for distant, or what they call ‘surface reading’ aided by computers; “Where the heroic critic corrects the text, a nonheroic [sic] critic might aim instead to correct for her critical subjectivity, by using machines to bypass it, in the hopes that doing so will produce more accurate knowledge about texts” (2009, p. 17). Whilst the piece is widely distributed as an argument for surface reading methodologies and makes substantial arguments for reading that “what lies in plain sight” because it “often eludes observation—especially by deeply suspicious detectives who look past the surface in order to root out what is underneath it.” (p. 18), the overarching narrative of Marcus and Best’s paper suggests that machine-reading literature can circumvent subjectivity and thus lead to a valid criticism. What is very present in its absence in Best and Marcus’ paper is a proposal of the technologies that afford such an objective reading, and furthermore, from own experience and those which I have read elsewhere, any data that is fed into such a machine for a surface reading must first go through the very humanistic process of selection – what data is to be analysed? The methods by which one selects a corpora are subject to varying degrees of subjective selection whether that is based on time period or any other thread of similarity.
Formalism:
Marcus and Best accusations are a mere resurrection of Formalist methods of literary analysis, only with added technologies – that very real fact that Stanford University (the spiritual homes of DH due to Moretti’s Lit Lab) held a 2015 conference entitled ‘Russian Formalism & the Digital Humanities’ not only shows a self-awareness of the natural affinity of DH and Formalist methods of literary analysis, but also that we may map the chronology that connects the two factions of the humanities. Russian Formalism materialised in the early part of the twentieth century and was, primarily, a reaction to wholly subjective methods of reading, or understanding, literature practiced by Symbolist methodologists. Symbolists placed high value on closely scouring a text in order to seek some universal truth that may (or may not) be found in obscure lexemes and evermore complicated literary techniques. Russian Formalism, on the contrary, regarded literature in a more scientific way – literature was there to be investigated through its language and its form. Marie-Laure Ryan, in the 1999 text Cyberspace Textuality: Computer Technology and Literary Theory, mirrors this concept in a modern context; “Computers were once thought of as number-crunching machines; but for most of us it is their ability to create worlds and process words that have made them into a nearly indispensable part of life. If computers are everywhere, it is because they have grown into ‘poetry machines’.” (1999, p. 1). Then, we can see, that both Russian Formalists and Digital Humanists, are interested in the literariness of literature, disengaging with the subjective notion of ‘literature’. Viktor Shklovsky states that literariness is merely the defamiliarisation of language; “Art exists that one may recover the sensation of life; it exists to make one feel things, to make the stone stony.” (1992, p. 277). Glen Worthy established a connection between Russian Formalism and the Digital Humanities in a Stanford Digital Humanities blog post in 2014; “I’m here to proclaim that the digital humanities are a 21st-century version of Russian Formalism of a hundred years ago.” outlining the continuation of the ‘objective’ literary analysis;
Marcus and Best accusations are a mere resurrection of Formalist methods of literary analysis, only with added technologies – that very real fact that Stanford University (the spiritual homes of DH due to Moretti’s Lit Lab) held a 2015 conference entitled ‘Russian Formalism & the Digital Humanities’ not only shows a self-awareness of the natural affinity of DH and Formalist methods of literary analysis, but also that we may map the chronology that connects the two factions of the humanities. Russian Formalism materialised in the early part of the twentieth century and was, primarily, a reaction to wholly subjective methods of reading, or understanding, literature practiced by Symbolist methodologists. Symbolists placed high value on closely scouring a text in order to seek some universal truth that may (or may not) be found in obscure lexemes and evermore complicated literary techniques. Russian Formalism, on the contrary, regarded literature in a more scientific way – literature was there to be investigated through its language and its form. Marie-Laure Ryan, in the 1999 text Cyberspace Textuality: Computer Technology and Literary Theory, mirrors this concept in a modern context; “Computers were once thought of as number-crunching machines; but for most of us it is their ability to create worlds and process words that have made them into a nearly indispensable part of life. If computers are everywhere, it is because they have grown into ‘poetry machines’.” (1999, p. 1). Then, we can see, that both Russian Formalists and Digital Humanists, are interested in the literariness of literature, disengaging with the subjective notion of ‘literature’. Viktor Shklovsky states that literariness is merely the defamiliarisation of language; “Art exists that one may recover the sensation of life; it exists to make one feel things, to make the stone stony.” (1992, p. 277). Glen Worthy established a connection between Russian Formalism and the Digital Humanities in a Stanford Digital Humanities blog post in 2014; “I’m here to proclaim that the digital humanities are a 21st-century version of Russian Formalism of a hundred years ago.” outlining the continuation of the ‘objective’ literary analysis;
“Like the Russian Formalists, we in the textual digital humanities focus on ‘The Word as Such’ (to use the title of a manifesto by two poets who were close comrades to the Formalists, Aleksei Kruchenykh and Velimir Khlebnikov); the advantage we claim in a particular digital approach is that we can do that at scale: our focus can be telescopic. But the object in view is very much the same as that of our predecessors.” (2014)
Whilst distant reading, and in fact, digital humanities as whole, does not seem to be a reaction to anything other than the precedence of canonical texts, it does seem to ask for a call to defamiliarise literature, to seek that which the literary critic cannot discover through meticulous study. Like the Russian Formalists, digital humanists insist on the implementation of scientific methods though, generally it is seen as an addition to the humanities rather than a replacement.
Rationale:
As mentioned in the introduction to this paper, I have conducted a number of digital humanities experiments throughout my research (largely done via Voyant Tools). My own personal area of interest lies in the Modernist period and I have a particular interest in the interwar novels of Elizabeth Bowen; this is where the bulk of my research has been conducted - including my undergraduate dissertation. However, my own dissertation was researched using application of literary theory and close reading methods of interpretation. The focus of this, separate, research project will be three interwar novels of Elizabeth Bowen; The Last September (1929), To the North (1932) and The Death of the Heart (1938). From this, I will attempt ‘data-mining’ on this small corpus of work to see if it is possible to ‘read’ the texts in a formalist way which would circumvent the subjective methods I have previously utilized. As I had used Voyant Tools before, I started by seeking out a list of ‘stop words’ (fig. 1) to utilise in an effort to avoid the unsatisfying prospect of being presented with a list of function words. The second task was to isolate the source data (the literature) from the introductions, forewords, images and all other literature that one would expect to find in an electronic novel and that could, potentially, corrupt a true reading. I inputted the list of stop words, as well as any names that cropped up frequently enough to skew the readings[1]. The first problem I encountered after I uploaded was that I could not seem to omit contracted words with apostrophes, such as “don’t” or “I’m”, from the cirrus and so, instead, had to manually omit these words using the ‘Terms’ tool and found that, then, the five most frequently used words in the corpus were (see fig. 1);
[1] If I was analysing only one text, I would have left in the names as this would have been an interesting look at the frequency of the character names and how they collocate with other lexemes.
As mentioned in the introduction to this paper, I have conducted a number of digital humanities experiments throughout my research (largely done via Voyant Tools). My own personal area of interest lies in the Modernist period and I have a particular interest in the interwar novels of Elizabeth Bowen; this is where the bulk of my research has been conducted - including my undergraduate dissertation. However, my own dissertation was researched using application of literary theory and close reading methods of interpretation. The focus of this, separate, research project will be three interwar novels of Elizabeth Bowen; The Last September (1929), To the North (1932) and The Death of the Heart (1938). From this, I will attempt ‘data-mining’ on this small corpus of work to see if it is possible to ‘read’ the texts in a formalist way which would circumvent the subjective methods I have previously utilized. As I had used Voyant Tools before, I started by seeking out a list of ‘stop words’ (fig. 1) to utilise in an effort to avoid the unsatisfying prospect of being presented with a list of function words. The second task was to isolate the source data (the literature) from the introductions, forewords, images and all other literature that one would expect to find in an electronic novel and that could, potentially, corrupt a true reading. I inputted the list of stop words, as well as any names that cropped up frequently enough to skew the readings[1]. The first problem I encountered after I uploaded was that I could not seem to omit contracted words with apostrophes, such as “don’t” or “I’m”, from the cirrus and so, instead, had to manually omit these words using the ‘Terms’ tool and found that, then, the five most frequently used words in the corpus were (see fig. 1);
- Room
- Eyes
- House
- Door
- Young
[1] If I was analysing only one text, I would have left in the names as this would have been an interesting look at the frequency of the character names and how they collocate with other lexemes.
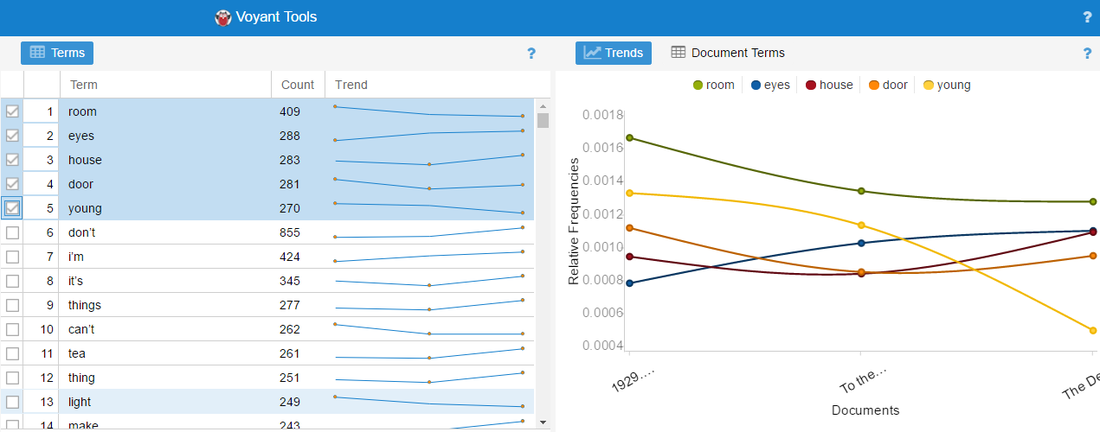
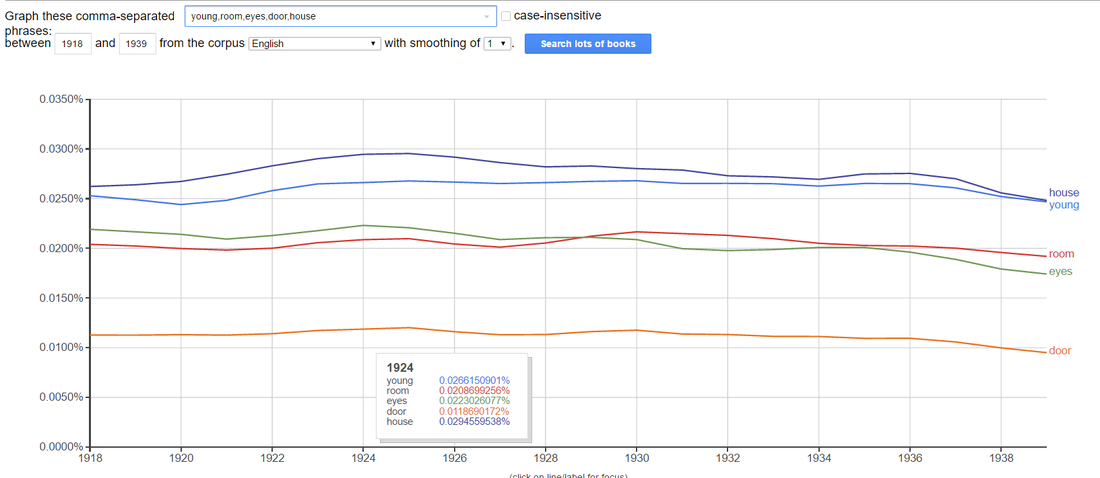
However, this left me with the very humanist problem of how to interpret this data once it has been revealed. My previous research has focussed on the problematic home spaces in Elizabeth Bowen’s interwar novels and while it is interesting that three of the five most frequently appearing words are related to home spaces, for the purposes of this experiment, I wanted to view the results as independent from this. Upon first examination, and of course dismissing anything I know about the author and her work, the five words we have unpicked from the corpus are all solid objective terms with the exception of the word ‘young’. Secondly, in the ‘Trends’ section, it is interesting to note that, from 1929 to 1938, the authors use of the word ‘young’ is in decline. In order to research these five words further, I entered them into Google’s Ngram Viewer to see the usage with English texts generally, in the interwar period (1918 – 1939) and found that in this the word ‘house’ appeared most frequently (fig. 2) but the words were quite consistent in their usage over this period.
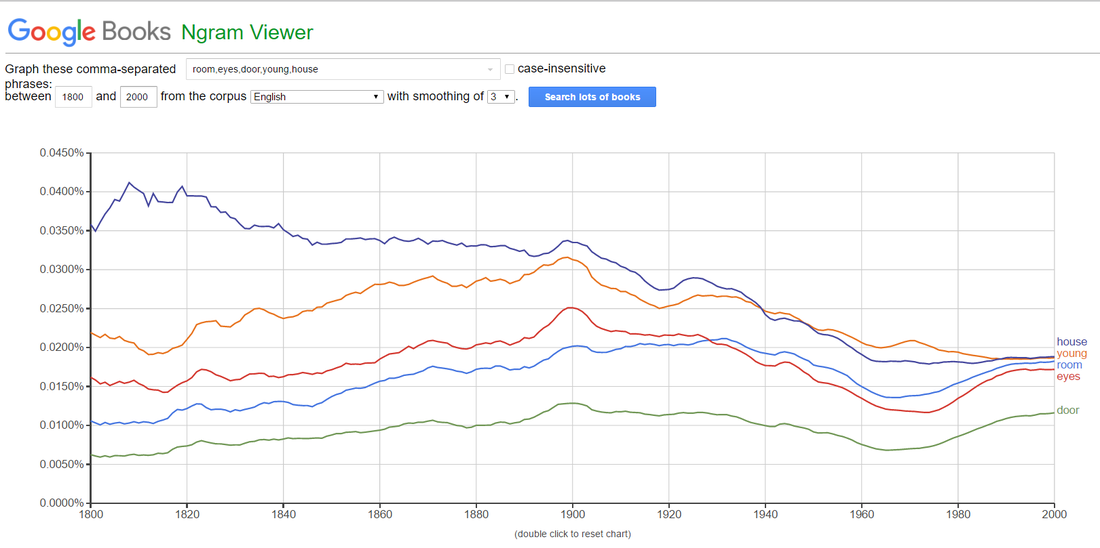
However, entering the words in the periodical boundaries set by Ngram Viewer (1800 – 2000) showed that all of these words enjoyed a simultaneous peak at the beginning of the twentieth century (fig. 3) but have been in decline since. What this shows is that, whilst a relatively unexplored writer, Bowen was writing, in general terms, similar themes to her peers.
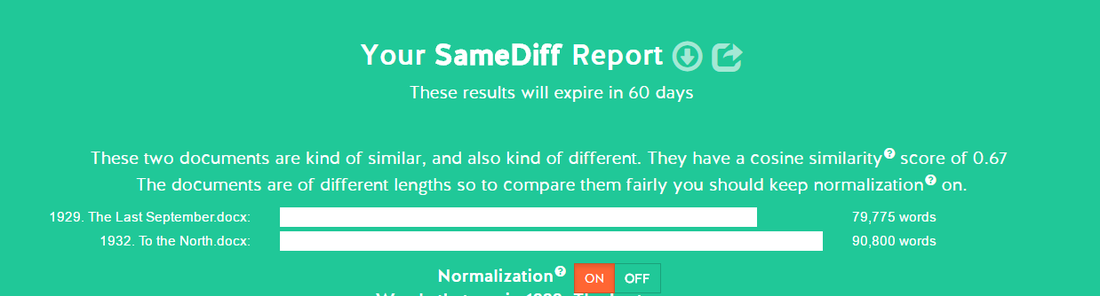
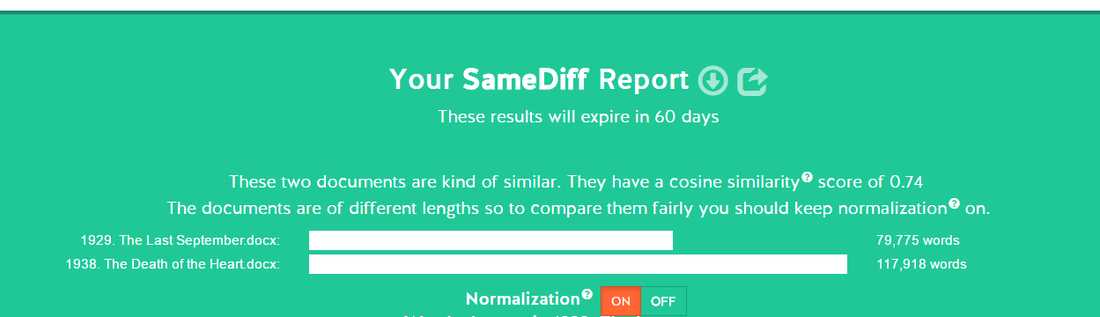
Using another digital tool, SameDiff, I could compare two of the texts any a time to see the cosine similarity of the texts. I first uploaded The Last September and To the North and the results showed that the texts were “kind of similar, and also kind of different” with a cosine[1] reading of 0.67 (fig. 4). I had anticipated greater similarities in these two texts as they were the closest publish dates.
[1] “the trigonometric function that is equal to the ratio of the side adjacent to an acute angle (in a right-angled triangle) to the hypotenuse.” (according to Google definitions)
[1] “the trigonometric function that is equal to the ratio of the side adjacent to an acute angle (in a right-angled triangle) to the hypotenuse.” (according to Google definitions)
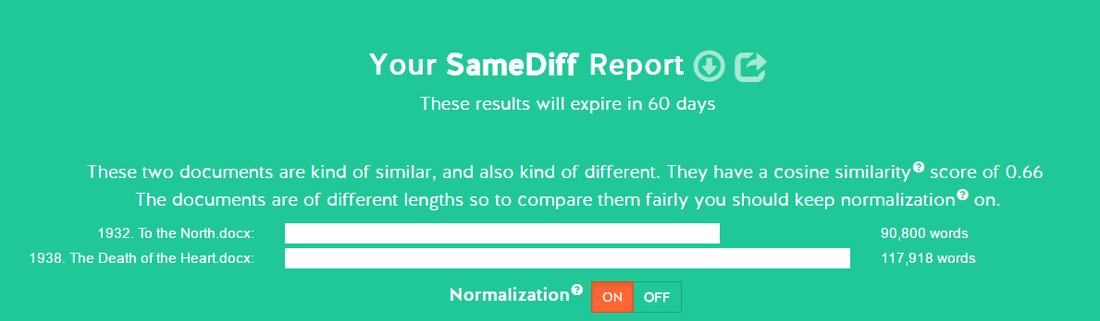
The second reading showed almost exactly the same reading for To the North and The Death of the Heart – the cosine reading was 0.66 (fig 5).
Surprisingly, the texts furthest away from each other chronologically had a much higher cosine score of 0.77 (fig. 6).
This experiment in distant reading produced fairly surprising results and certainly, none of the information gleaned could be replicated by a close reading. I think this could have produced entirely more surprising results had I used a larger corpora and used an author whose works I was unfamiliar with – for me this was more of an exercise in confirming what I suspected already but was able to quickly and concretely confirm. As an additional commentary, both Samediff and Google’s NGram Viewer are simple, they work well and produce coherent results and use an accessible interface. Voyant Tools suffers from intermittent failures making a laborious task such as feeding data and entering stop-words untenable. Though my research involved in searching for and reviewing the digital tools to use was extensive, there lies a fundamental issue with usability and accessibility.
Conclusion:
Throughout this essay, I have sought to present an overview, including many criticisms, of the concept of distant reading as a tool for literary analysis. Within this, I have considered how repositioning the humanities as a scientific discipline overtly rouses outmoded methods that are associated with Formalism – the digital humanities movement seems to be working towards a new Formalist approach (not New Formalist). I have also documented my own investigation with an, admittedly, small corpus of texts which, while somewhat illuminating, confirmed my suspicions that the widely-available distance reading tools are in their infancy and, as yet, fail to convince the novice digital humanist that ‘reading’ in this way could ever fully replace current literary interpretation methods. Computational distance reading, or data mining, in particular provides a significant argument by which we can measure the leaning of the discourse surrounding literary criticism and, more alarmingly, the robust apathy for traditional literature analysis. Whilst in this paper, I have rejected a systemic shift away from tradition within the humanities, I do advocate a disturbance that will not only provoke an inward reflection of the discipline but could, potentially, engage those who would traditionally be outside of the area of literary criticism.
Throughout this essay, I have sought to present an overview, including many criticisms, of the concept of distant reading as a tool for literary analysis. Within this, I have considered how repositioning the humanities as a scientific discipline overtly rouses outmoded methods that are associated with Formalism – the digital humanities movement seems to be working towards a new Formalist approach (not New Formalist). I have also documented my own investigation with an, admittedly, small corpus of texts which, while somewhat illuminating, confirmed my suspicions that the widely-available distance reading tools are in their infancy and, as yet, fail to convince the novice digital humanist that ‘reading’ in this way could ever fully replace current literary interpretation methods. Computational distance reading, or data mining, in particular provides a significant argument by which we can measure the leaning of the discourse surrounding literary criticism and, more alarmingly, the robust apathy for traditional literature analysis. Whilst in this paper, I have rejected a systemic shift away from tradition within the humanities, I do advocate a disturbance that will not only provoke an inward reflection of the discipline but could, potentially, engage those who would traditionally be outside of the area of literary criticism.
