Quantitative/Algorithmic Literary Criticism
- An Exercise in Defamiliarization.

Background:
Close reading, as a method of interpretation, has been, and continues to be, a key facet of literary study as evidently, the method wholly compliments the medium. The thorough analysis of a text, or texts, is, for the most part, a technique aimed at the identification of themes, motifs, and symbols which can then be used for literary and critical comparison or interpretation. However, the possibilities that scholars have been afforded with the use of digital tools means that one has the potential to scan, extract and then, analyse (what I will refer to as the ‘sober’ data) tremendous amounts of digitized literary texts. This trend of extracting big data from distant ‘reading’ techniques gained significant ground from the work in Franco Moretti’s Graph, Maps, Trees (2007). In this influential text, Moretti proposed distant reading methods (for text) which shifted the long-established traditions of ‘close reading’ into the digital age and thus, encouraging wider and more distant techniques to map the sober data of a text in a more objective manner in order to visualize the text data.
Rationale:
My own report aims to utilize some of the tools which have been developed to aid a distance reading of a corpus of texts. I have chosen to investigate the 'big data' of ten prominent interwar novels published between 1920 and 1929. As well as satisfying my own personal interest in this literary era, I will also use the results to determine any similarities, themes, motifs, words or relationships that are typically obscured in a ‘close reading’. Faithful to my own earlier research, I will be pursuing instances of language associated with trauma as a consequence of an uncertain world and as was synonymous with this interwar period. Whilst I understand that my corpus is relatively narrow, I have chosen texts from a variety of nations in the ten year period to better understand the effects on an international basis.
1920: The Age of Innocence - Wharton, E. | 1921: Chrome Yellow - Huxley, A. | 1922: The Beautiful & the Damned - F. Scott Fitzgerald
1923: Zeno's Conscience - Svevo, I. | 1924: We - Zamyain, Y. | 1925: Mrs Dalloway - Woolf, V. | 1926: The Sun Also Rises - Hemmingway, E. | 1927: The Twelve Chairs - Ilf & Petrov | 1928: Lady Chatterley's Lover - Lawrence, D.H. | 1929: The Last September - Bowen, E.
Close reading, as a method of interpretation, has been, and continues to be, a key facet of literary study as evidently, the method wholly compliments the medium. The thorough analysis of a text, or texts, is, for the most part, a technique aimed at the identification of themes, motifs, and symbols which can then be used for literary and critical comparison or interpretation. However, the possibilities that scholars have been afforded with the use of digital tools means that one has the potential to scan, extract and then, analyse (what I will refer to as the ‘sober’ data) tremendous amounts of digitized literary texts. This trend of extracting big data from distant ‘reading’ techniques gained significant ground from the work in Franco Moretti’s Graph, Maps, Trees (2007). In this influential text, Moretti proposed distant reading methods (for text) which shifted the long-established traditions of ‘close reading’ into the digital age and thus, encouraging wider and more distant techniques to map the sober data of a text in a more objective manner in order to visualize the text data.
Rationale:
My own report aims to utilize some of the tools which have been developed to aid a distance reading of a corpus of texts. I have chosen to investigate the 'big data' of ten prominent interwar novels published between 1920 and 1929. As well as satisfying my own personal interest in this literary era, I will also use the results to determine any similarities, themes, motifs, words or relationships that are typically obscured in a ‘close reading’. Faithful to my own earlier research, I will be pursuing instances of language associated with trauma as a consequence of an uncertain world and as was synonymous with this interwar period. Whilst I understand that my corpus is relatively narrow, I have chosen texts from a variety of nations in the ten year period to better understand the effects on an international basis.
1920: The Age of Innocence - Wharton, E. | 1921: Chrome Yellow - Huxley, A. | 1922: The Beautiful & the Damned - F. Scott Fitzgerald
1923: Zeno's Conscience - Svevo, I. | 1924: We - Zamyain, Y. | 1925: Mrs Dalloway - Woolf, V. | 1926: The Sun Also Rises - Hemmingway, E. | 1927: The Twelve Chairs - Ilf & Petrov | 1928: Lady Chatterley's Lover - Lawrence, D.H. | 1929: The Last September - Bowen, E.
|
|
Methodology:
I started this process by converting the texts from epub to a more universal format, PDF, using software from Calibre. The first tool I used to analyse this corpus was Voyant Tools. Here, I uploaded the ten Modernist novels and the tool then produced several reports. Whilst this was an interesting foray into the language used by authors in this ten-year period, the results were disappointingly predictable (even using the stop-words option). The most used words according to the report; like (2980); time (1790); little (1657); know (1608); went (1496). |
I then used these words in Google’s Ngram viewer (Fig: 1) and inputted these five lexemes to track their use more widely within the same period (1920 – 1929). The results were similar but with one minor disparity – the word ‘time’ occurs much more frequently in the literature of the period than in the ten novels I chose. Whilst this is interesting, it failed to ‘change’ the way in which I would potentially approach any of the novels and nor did it offer anything unexpected.
Fig: 1
Returning to Voyant Tools, I thought it conducive to my study to omit those which I deemed to be ‘function’ words, - I excluded all character names and the following frequently used words:
‘said’ | ‘like’ | ‘know’ | ‘thought’ | ‘looked’
This omission produced a somewhat more useful variety of words that appeared throughout the corpus and I was left with the following;
time (1671); little (1561); went (1384); man (1349); just (1261)
‘said’ | ‘like’ | ‘know’ | ‘thought’ | ‘looked’
This omission produced a somewhat more useful variety of words that appeared throughout the corpus and I was left with the following;
time (1671); little (1561); went (1384); man (1349); just (1261)
In particular, the frequency of the words 'little' and 'time' were of interest, and pursuing this further, I decided to break down the results. I started by separating the corpus into two smaller corpus'; one would span 1920 - 1924 (Fig: 2) and the second would span 1925 - 1929 (Fig: 3). The use of the word 'little' was consistent in its appearance, the second most frequently used work in the separated corpus'.
|
time : little : man : eyes : just
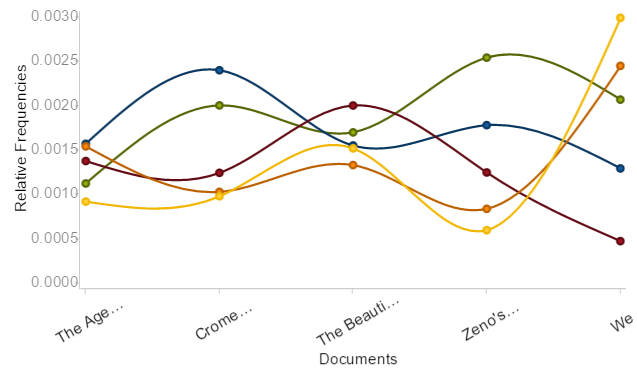
Fig: 2 - 1920 - 1924
|
went : little : time : come : man
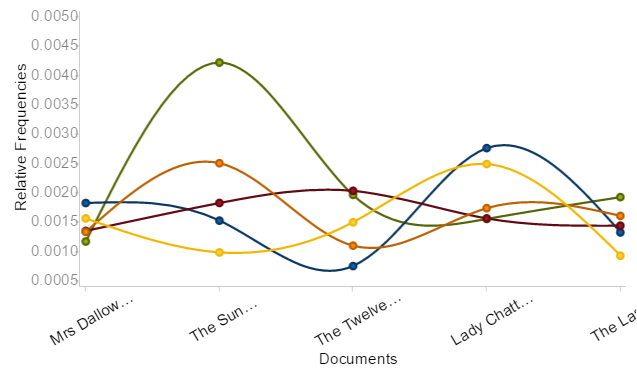
Fig: 3 - 1925 - 1929
|
Upon deconstructing these two key terms, I returned to Ngram to trace the use of these words (Fig: 4) from 1800 - 2008 (the tools end date) and whilst the word 'time' has been used consistently in texts throughout this period, the word 'little' and been in significant decline since 1900 with a small resurgence in 2007.
Fig: 4
Comment:
As a distinct feature of Modernist fiction, time is symbolic, fragmented and becomes an abstract concept which, as is evidenced on the Ngram, continues into Postmodernism and continues to be a source of literary focus to the present day. As this study has also shown, ‘time’, as a lexeme, appeared frequently in this specific corpus of Modernist texts. Whilst my aim is not to turn this exercise in distant reading into a close reading, it is worth noting Jurgen Habermas’ comments of the significance of time in this period complement and support the evidence we have extracted from the data mining; ”…the modern world is distinguished from the old by the fact that it opens itself to the future, the epochal new beginning is rendered constant with each moment that gives birth to the new'' (1987, p. 6).

Review:
Conducting this study and analyzing the subsequent results have shown the potential of Franco Moretti’s ‘distance reading’ method and indeed, I have encountered studies that have produced much more fruitful results than those that I have found within my own though, admittedly, these have seemed to use much more specific or voluminous corpus’. This is not to disregard the flaws, though not owed wholly to Moretti’s method. The tool I used to conduct the majority of the research, Voyant Tools, was unreliable and I often had to reload the texts which was frustratingly slow and thus, wasted time. I did attempt to counter this by using other tools listed on Alan Lui's 'Digital Humanities Tools' but I had little success with most of these. I found that the majority of tools listed were either no longer online or were aimed at a much more experienced digital humanist than I. In spite of these struggles, I found Google’s Ngram Viewer reliable and accessible, though the ‘reading’ is unclear and the corpus it analyses is ungovernable and esoteric – users have no clear indication on the amount of texts analysed, nor which texts are included and I found no way to determine this. Critically, the “swarms of hybrids and oddities” (2013, p.181) that Moretti described (negative connotations aside) and that are created in such a study need a humanist approach to interpretation – without a humanist approach the “hybrids and oddities” are nonsense.
Conducting this study and analyzing the subsequent results have shown the potential of Franco Moretti’s ‘distance reading’ method and indeed, I have encountered studies that have produced much more fruitful results than those that I have found within my own though, admittedly, these have seemed to use much more specific or voluminous corpus’. This is not to disregard the flaws, though not owed wholly to Moretti’s method. The tool I used to conduct the majority of the research, Voyant Tools, was unreliable and I often had to reload the texts which was frustratingly slow and thus, wasted time. I did attempt to counter this by using other tools listed on Alan Lui's 'Digital Humanities Tools' but I had little success with most of these. I found that the majority of tools listed were either no longer online or were aimed at a much more experienced digital humanist than I. In spite of these struggles, I found Google’s Ngram Viewer reliable and accessible, though the ‘reading’ is unclear and the corpus it analyses is ungovernable and esoteric – users have no clear indication on the amount of texts analysed, nor which texts are included and I found no way to determine this. Critically, the “swarms of hybrids and oddities” (2013, p.181) that Moretti described (negative connotations aside) and that are created in such a study need a humanist approach to interpretation – without a humanist approach the “hybrids and oddities” are nonsense.
All banner artwork created by Stephanie Darke. 2016
DISCLAIMER: All videos, unless created by Stephanie Darke, are linked directly from Youtube & Vimeo. At the time of publishing, all are available in the public domain. All images, unless created by Stephanie Darke, are referenced and linked on the resources page
DISCLAIMER: All videos, unless created by Stephanie Darke, are linked directly from Youtube & Vimeo. At the time of publishing, all are available in the public domain. All images, unless created by Stephanie Darke, are referenced and linked on the resources page
